
Pour la deuxième année consécutive, l’étude publiée par le magazine « Les Décideurs » classe CEPTON parmi les cabinets de conseil en Santé et Industrie Pharmaceutique dans la catégorie « incontournables » (2019). C’est encore une fois une formidable reconnaissance pour le travail et les efforts de notre équipe.
Tag: Pharma
L’IA dans la découverte de médicaments: les robots découvriront-ils les entités moléculaires nouvelles de demain ? (article en anglais)
By Valentin Fleury and Marc-Olivier Bévierre – CEPTON Strategies
Artificial Intelligence (AI) is taking the old concept of “Rational Drug Design” to a new dimension. The time has not come yet where robots will replace medicinal chemists, but drug discovery in the small molecule area is on the brink of a radical transformation.
The economist Joseph DiMasi (Director of the Tufts Center for the Study of Drug Development) published a study [1] highlighting a multiplication by 6, between 1991 and 2013, of the costs of research and development engaged for a single molecule to reach the market: from ~€450m in 1991 versus ~€2,560m in 2013.
According to Deloitte’s annual report “Measuring the return from pharmaceutical innovation”, the return on investment of the big pharmaceutical companies is steadily decreasing (10% in 2010 versus 3.2% in 2017), thus predicting a possible shift in negative ROI by the beginning of the 2020 decade. This efficiency crisis shakes the traditional model of the pharmaceutical R&D to such an extent that it becomes urgent to adapt it.
The long and expensive way leading to drug discovery…
The research and discovery of small molecules (as opposed to biologics, which are bigger molecules, more complex, and less stable) can be seen as a succession of steps of molecules’ identification and selection. It is usually segmented into four major steps:

Figure 1 – Drug Research and Discovery steps
Lead optimisation remains a puzzle for chemists that compares to the Rubik’s cube: maximise a parameter, you will degrade another one. This step alone concentrates 20% of total research and development costs.
Next steps are more widely known to the general public: in preclinical research, the best molecules are tested on vivo models to assess their toxicity, pharmacology and pharmacokinetics. Finally, one (or more) drug candidate enters the human clinical trial phase. This is the “development” part which usually lasts several years (10 years on average, according to Bernstein Research) and accounts for 60% of total R&D costs.
Why is pharma R&D productivity declining?
The reasons for this decline in productivity are numerous and have been intensively discussed [2]. Among them, two reasons stand out, in our opinion.
First: pharmaceutical R&D addresses more complex pathological processes today than in the past. In other words, we have found medicines for all the ‘easy diseases’, and we are now facing the “difficult” ones.
The second reason is based on a technological bias: the scientific and technical progress of the 80s and 90s allowed the industrialisation of certain research stages. For instance, High Throughput Screening (HTS) or more recently DNA-encoded chemical libraries have artificially inflated the number of leads generated, by increasing the capacity of the filtration stages, without increasing their quality in similar proportion. Thus, more molecules, not better ones, have been pushed through later stages of development, generating more spending without better results in the end.
Thus, the pharmaceutical industry is now seeking to reduce operational costs and improve cycle time within research and development. And AI’s ability to reduce drug development times is increasingly established.
The potential of AI in drug discovery
To improve productivity in small molecule discovery, the key challenge is to find a molecule (the identification part of the process) that maximizes a large number of very diverse criteria, which will be tested sequentially, one after the other (the selection part). Artificial Intelligence (AI) makes it possible to build holistic models for the design of new drugs where these tests can be performed simultaneously, in silico.
The use of deep learning algorithms in drug discovery became widespread in 2012, after Georges Dalh won the Merck Molecular Activity Challenge by demonstrating the effectiveness of little trained deep neural networks to predict the activity of a molecule starting from its structure [3]. This has automated a discipline well known to chemists: QSAR (Quantitative Structure-Activity Relationship).
In 2016, in an article entitled « Automatic chemical design using a data-driven continuous representation of molecules« , Alan Aspuru-Guzik et al.[4] describe a method of continuous and multidimensional representation of the chemical space using deep neural networks. This method allows a simpler, faster and more comprehensive exploration of the chemical space (estimated at 1060 molecules potentially usable as a drug), and ultimately, the generation of virtual molecules previously inaccessible even via the largest databases (containing about 108 molecules).
A case study…
One of our clients, IKTOS, a French start-up founded in 2016, has developed an AI technology capable of generating molecules under the constraint of a set of physicochemical and biological characteristics, according to in silico predictive models of such characteristics.
IKTOS technology is based on the interweaving of three algorithms, which are orchestrated to enable an efficient exploration of the chemical space in an iterative manner and enable the identification of optimal in silico compounds in a few hours of computation.
The first is a generative model: trained on databases containing several million chemical compounds, it can « build » virtual molecules located anywhere in the chemical space (implementing a principle close to that proposed by Gomez-Bombarelli et al.).
The second is a predictive algorithm: trained on a customer database that contains already available and tested molecules, those models can predict the physicochemical and pharmacological properties of a molecule only from its chemical structure.
The third is the reinforcement algorithm: the reinforcement component uses the information (scores) provided by the predicted models on the previous sets of generated molecules to modify the weights of the generative model in order to orientate the molecule generation in the right direction.
This technology has demonstrated[5] its effectiveness through a collaboration with a major pharmaceutical company. For 10 years, the chemist team had tried to make compounds maximising a set of 11 biological activity criteria. Among the 900 compounds that they had synthesized and tested; they were not able to find any molecule hitting more than 9/11 success criteria. In just a few days, IKTOS technology generated 150 virtual molecules which were predicted to meet all 11 criteria, in silico. Out of those 150 molecules, 11 were selected (based on their synthetic accessibility and originality), synthesized by the chemists, and tested on all 11 criteria. 9 molecules were found to maximize 9 criteria, 3 to maximize ten criteria, and 1 molecule was found to be good on all 11 success criteria. It took only a few days for an AI, and 11 molecules, to achieve better results than what had been achieved by a team of chemist experts over 10 years of benchtop research and 900 trials of molecules.
An emerging field attracting massive investments
The use of artificial intelligence in small molecule research is quite new, and it is still difficult to figure out how far it will go. We have identified -and often met as well- more than a hundred companies (mainly start-ups) at the crossroad of pharmaceutical R&D and AI. Many start-ups are flaunting attractive technologies, but those who are really able to deliver high value-added and actionable results are still few in number. In addition, the still limited number of success stories and the confidentiality that surrounds most of them contribute to a lack of clarity among medicinal chemists around the applications of AI in their profession. In fact, big pharma is still seeking to understand the possible applications of AI, and to evaluate existing technologies and stakeholders.
Numerous partnerships have been signed recently, demonstrating the growing interest in the area (Sanofi with Exscientia and Recursion, Merck with Atomwise, GSK with Cloud pharmaceuticals, InSilico Medicine and Exscientia, Iktos and Janssen, Iktos and Merck). The increasing number of scientific publications in recent years also reflects the enthusiasm of the scientific community and the industry. In addition, private investments are accelerating (~$30m invested in 2012 versus ~$500m and ~$800m in 2014 and 2016 respectively). The enthusiasm of investors is all the greater when certain start-ups, initially service providers of R&D for the pharmaceutical industry, develop their own pipeline of molecules and thus compete frontally with traditional biotech startups. Benevolent AI, whose first clinical trials on Parkinson’s disease began in 2018, holds 20 molecules in the preclinical phase, and has recently raised $115m. Today, it is valued at $2bn.
Towards automated drug discovery?
Certain companies (like SRI or Catapult Medicine Discovery) aim at developing a fully automated research workflow, from automated design and retrosynthesis to robotised synthesis and tests. We are not among the few utopians who believe in the total automation of pharmaceutical drug discovery. Nevertheless, AI will certainly contribute to deeply transforming pharmaceutical research. As some say, “AI will not replace medicinal chemists, but medicinal chemists who use AI will replace those who don’t”. Investments of pharmaceutical companies in AI are nibbling budgets of benchtop research and computational chemistry, progressively driving research activities to more in silico and automated methods. Today, most of the major names in the industry develop partnerships with companies mastering these technologies. The question remains whether they will try to internalise it or not. If not, we expect to see in the next few years the emergence of a new model of AI-based biotech start-ups, with highly automated discovery processes, and sufficient funding to develop their own pipeline.
___________________________________________________________________________________________________________
Sources:
[1] DiMasi JA, Grabowski HG, Hansen RA. “Innovation in the pharmaceutical industry: new estimates of R&D costs”. Journal of Health Economics 2016
[2] J.W. Scannel et al. “Diagnosing the decline in pharmaceutical R&D efficiency”. Nature 2012
[3] George E. Dahl et al. “Deep Neural Nets as a Method for Quantitative Structure-Activity Relationships”. Journal of Chemical Information and Modeling 2015
[4] Alan Aspuru-Guzik et al. « Automatic Chemical Design Using a Data-Driven Continuous Representation of Molecules”. ACS Central Science 2018
[5] “Deep Learning For Ligand-Based De Novo Design In Lead Optimization: A Real Life Case Study”. Iktos and Servier Poster 2018
L’importance croissante des Données en Vie Réelle, des stratégies réglementaires à la gestion du patient (article en anglais)
By Alexandre Bréant and Marc-Olivier Bévierre – CEPTON Strategies
The excitement and controversies that ensued the presentation of the Apple Heart Study at the AAC congress earlier in March show how data generation is evolving in the pharma industry: health data, coming from a non-medical device, harvested by a non-medical company.
How can Real-World data and Real-world Evidence be integrated in pharma companies’ best practice and help them redefine what standard of care means for the medical community and the patients?
Summary
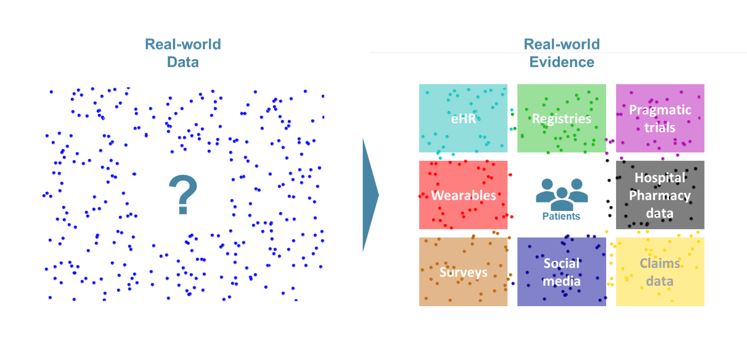
Real-world evidence (RWE) is the evidence derived from real-world data (RWD), which is any kind of health-related data not coming from a clinical trial. Far from opposing to one another, real-world data and data from clinical trials complement each other. Together, they could reduce time to market of innovative solutions, help both the payer and the industry derive better value from treatments, inform clinical practice and optimize treatment allocation to the patients most-likely to have the highest benefit/risk ratio.
However, to realize the full potential of RWD, changes need to happen in both the public (regulatory, payers, healthcare infrastructure) and private side to define the data standards as well as the best practice to collect, consolidate, present and use these data.
With no doubt, companies integrating RWE at each step of the value chain will gain a competitive advantage but this requires an in-depth change in the way data are strategically considered and operationally collected, managed and analyzed.
Introduction
Sometimes, there is merit in comparing apples with oranges. Or more accurately a quart of cider vs. two oranges and a lemon daily, as did James Lind when searched for a cure to scurvy in 1747. Scurvy is a disease resulting from lack of vitamin C that plagued sailors during the Age of Sail. Lind took 12 scorbutic sailors, with “cases as similar as [he] could have them” and split them into 6 groups of 2, gave each group a different treatment (cider, citrus fruits, vinegar, elixir vitriol or mere sea water) and compared the health improvement in each group. This experiment is considered as the first controlled clinical trial [i] and since then, the methods for clinical trials have been refined and improved (blinding of patients and health-care providers, randomization and stratification, advanced statistical analysis, reporting guidelines…) to reach what is now considered the gold standard of evidence generation and the foundation of evidence-based medicine: the double-blind, randomized controlled trial (RCT).
However, while RCT’s praised methodology reduces the risk of getting false positive or false negative results, it does so at the expense of its generalizability to a broader population of patients: for a given treatment, efficacy could substantially differ from effectiveness, as nicely illustrated in the British Medical Journal [ii]. Indeed, efficacy is measured under almost ideal conditions on a carefully selected population in an RCT while effectiveness is evaluated in conditions of clinical practice on the more variable population of patients that exist in real-life.
In an ideal world, data should combine the richness of the real-world setting with the objectiveness of the clinical trial setting. With the increased digitization of the world [iii], will real-world data be able to fulfill this ambitious objective?
What are real-world data and real-world evidence?

As defined by the Innovative Medicine Initiative (IMI), Real-World Data (RWD) are “An umbrella term for data regarding the effects of health interventions (e.g. safety, effectiveness, resource use, etc) that are not collected in the context of highly-controlled RCT’s”. Real-world Evidence (RWE) is the evidence derived from the analysis and/or synthesis of RWD.
This definition makes it obvious that RWD and data from RCT are complementary subsets of the overall health data available. RWD can come from several sources and be split in 3 different types (see Box 1).
How can RWE be used?
RWD is, fundamentally, data, which means they could be useful, in principle, anywhere data coming from RCT are currently used (regulatory decision for marketing authorization, HTA evaluation for pricing and reimbursement, guideline elaboration and treatment decisions) and even beyond, as it could help empowering the patients.
Regulatory
The primary concern of the regulator is the evaluation of the benefit risk ratio throughout the product lifecycle, so they welcome any reliable information that improves their assessment. Therefore, the EMA considers that, for regulatory purposes “leveraging RWE is a need – and an achievable goal”[vii]. For example, RWE could be used in evidence generation:
– Before marketing authorization (i.e. to obtain new indication or expand indications):
- To demonstrate efficacy (e.g. External control for very rare conditions, complement or even replace RCT [viii] in some cases)
- To enrich safety data
– After marketing authorization:
- For post-approval Efficacy [1] or Safety Studies (PAES/PASS)
- For Effectiveness [2] demonstration
For example, today, home hemodialysis (HHD) is a treatment reserved for young and autonomous Chronic Kidney Disease (CKD) patients. However, most nephrologists believe that with smart telemonitoring services HHD could safely be extended to sicker patients (older and/or with comorbidities). In this case, the generation and analysis of RWD on compliance (number and duration of dialysis sessions), efficacy (ultrafiltration rate), and safety (vascular access state) would allow both nephrologists and patients to safely consider HHD as a relevant dialysis modality.
Market access
Payers aim at maximizing public health within the constraints of their budget. This mandate is becoming increasingly difficult with the high price of innovative treatments and the ongoing demographic mutation of developed economies (rise of chronic diseases, increased proportion of senior citizens…).
To optimize spending, they more and more often rely on managed entry agreements (MEA) with pharmaceutical companies, such as value-based pricing or outcome-based contracts. The idea behind the MEA is simple: if a certain level of effectiveness is not met by a predefined deadline, the pharmaceutical company should reimburse all or some of the treatment for that patient.
For example, in 2015 Janssen agreed on rebates on Olysio to the NHS if the patient is not cured within 12 weeks [ix]. To limit the likelihood of a failure (and a rebate), Janssen provided a companion blood test to help predict whether a patient would respond to the treatment, thus limiting the number of patient’s futile exposure to a serious and expensive treatment. Real-world evidence can also be used for pay-for-performance schemes when the situation is not as black and white as the Olysio case, where the cure is the expected outcome. In 2007, a pay-for-performance scheme was negotiated between Janssen and the NHS for Velcade in multiple myeloma. In this scheme, “the company will provide replacement stock or credit for those patients at first relapse who fail to respond to Velcade”, response being measured as the reduction of at least 25% of a serum biomarker [x]. With this response-based rule, Velcade became cost-effective despite their high then-price and was granted reimbursement.
Clinical practice
Improved access to RWE could also mean a continuous and hyperlocal analysis of data, which could guide treatment decision on what works best on specific patient populations:
- Taking into account the geographical, social and personal components [xi] to select a given treatment course or sequence (RWE were cited as the most important data to inform treatment decision, before RCT data, in a recent survey [xii])
- Identify subpopulations or relevant biomarkers [xiii]
- Improve original drug schedule to improve efficacy and or adverse event management [xiv]
Patient empowerment
Whether it is through the extension of available indications, a better reimbursement or improved care, Real-world evidence generated from Real-world data are ultimately benefiting the patients. However, on the patient side, the mere production of RWD could also be beneficial, as the involvement of the patients in their care boosts adherence and helps detect complications and signs of relapse in real-time, to avoid wasting precious time at critical moments. For example, symptom monitoring through an online portal not only improves quality of life, patient satisfaction and ER utilization but also has a significant impact on extending patient’s overall survival [xv].
What are the key issues and opportunities for companies willing to use real-world data?
The EU has started funding many initiatives to bolster the generalization of RWD and RWE, and the EMA is strongly advocating for their use on a routine basis. However, Pharma companies should also marshal their resources to ensure they can seize the opportunity to improve their practice at every steps of their operations:
– Improve clinical trials through:
- Better understanding of patients and medical community needs
- Combining traditional RCTs, adaptative trials, pragmatic trials and collect data from more sources
- Pooling data from several trials to speed up trial execution and reduce unnecessary patient exposure
– Enrich Payer value proposition:
- Narrow the gap between efficacy and effectiveness
- Track the actual economic value of their treatments or of their competitors
– Isolate better responding population through biomarkers or socio-economic data
– Engage with patients in a compliant fashion, to better gather feedback and maximize treatment benefit
We see 3 key topics to be addressed by companies willing to build expertise in RWD:
1. Technical
Real-world data are rarely as clean as RCT data, since RCT data is homogenous, recorded in controlled conditions on well-defined patients, with identified confounding factors and strategies to minimize their influence. This implies several technical challenges to collect RWD in a timely and standardized manner despite the variability of the points of care, store them properly, especially within the framework of GDPR in Europe.
2. Talent
Parallel to the technical challenges mentioned above, analyzing RWD is more complicated than designing a priori a robust statistical analysis plan. It requires expert data scientist profiles, combining strong biostatistics knowledge and IT acumen to exploit the data lakes of structured and unstructured data of uneven quality.Beyond pure technical profiles, a new breed of cross-functional coordinators will be needed to ensure smooth information flow and alignment between all internal (R&D, Medical affairs, Regulatory affairs, Market Access, Patient centricity, Public affairs, IT, BI and analytics, Legal…) and external stakeholders (Regulators, Payers, Scientific and patient organizations, Insurers, Hospitals, …).
3. Governance
The importance of the coordinator position will go hand in hand with profound changes in governance, especially regarding the strategic role of these data on how to prioritize assets, to decide on the focus of future acquisitions or in-licensing. The questions of “who owns the data”, “what can be done with it” will be central in the generation and use of RWE, which will not accommodate the frequent siloed ways of working still at play in many pharma companies.
Conclusion
Far from opposing to one another, real-world data and data from clinical trial complement each other. Together, they could reduce time to market of innovative solutions, help both the payer and the industry derive better value from the treatments, inform clinical practice and optimize treatment allocation to the patients most-likely to have the highest benefit/risk ratio. However, to realize the full potential of RWD, changes need to happen in both the public (regulatory, payers, healthcare infrastructure) and private side to define the data standards as well as the best practice to collect, consolidate, present and use these data. With no doubt, companies integrating RWE at each step of the value chain will gain a competitive advantage but this requires an in-depth change in the way data are strategically considered and operationally collected, managed and analyzed.[1] Efficacy: benefits measured in a RCT setting[2] Effectiveness: benefits measured in clinical practice
___________________________________________________________
Sources :
[i] A. Bhatt, Perspect Clin Res. 2010 Jan-Mar; 1(1): 6–10.
[ii] Yeh et al. BMJ 2018;363:k5094
[iii] https://www.politico.eu/sponsored-content/making-the-eus-health-systems-fit-for-the-21st-century/, consulted March 12, 2019
[iv] Eichler et al, Clinical trials 2018 Vol 15 (S1) 27-32
[v] https://edps.europa.eu/data-protection/our-work/subjects/health_en consulted March 12, 2019
[vi] https://arstechnica.com/gadgets/2018/10/amazon-patents-alexa-tech-to-tell-if-youre-sick-depressed-and-sell-you-meds/ consulted March 12, 2019
[vii] Eichler, Real-World Evidence – an introduction; how is it relevant for the medicines regulatory system, EMA, London, April 2018
[viii] https://www.fdli.org/2018/08/update-fdas-historical-use-of-real-world-evidence/, consulted March 13, 2019
[ix] https://www.fiercepharma.com/pharma/janssen-agrees-to-rebate-cost-of-olysio-to-england-s-nhs-if-it-doesn-t-work consulted March 12, 2019
[x] https://www.nice.org.uk/guidance/ta129/documents/department-of-health-summary-of-responder-scheme2
[xi] https://www.medscape.com/viewarticle/910447, consulted March 16,2019
[xii] http://www.volumetovaluestudy.com/docs/Tracking%20the%20Shift%20From%20Volume%20to%20Value%20in%20Healthcare.pdf, consulted March 13, 2019
[xiii] Fiore et al. Clin Pharmacol Ther. 2017;101(5):586-589.
[xiv] Boegemann et al. Anticancer Research November 2018 vol. 38 no. 11 6413-6422
[xv] https://meetinglibrary.asco.org/record/147027/abstract, consulted March 13, 2019
CEPTON parmi les cabinets de conseil incontournables en Santé et Industrie Pharma selon le magazine « Les Décideurs »
Pour la deuxième année consécutive, l’étude publiée par le magazine « Les Décideurs » classe CEPTON parmi les meilleurs cabinets de conseil en Santé et Industrie Pharmaceutique (2018). Douze ans après la création du cabinet, c’est une formidable reconnaissance pour le travail et les efforts de notre équipe.
CEPTON classé par la magazine « Capital » parmi les meilleurs cabinets de conseil dans les catégories « Stratégie » et « Santé ».
Après seulement 10 ans d’existence, CEPTON vient déjà d’être classé parmi les meilleurs cabinets de conseil dans les catégories « Stratégie » et « Santé », selon l’enquête indépendante du magazine CAPITAL parue en octobre 2016, qui a interrogé plus de 4000 personnalités du monde des affaires en France. Tout l’équipe de CEPTON est très fière de cette reconnaissance qui consacre dix ans d’efforts soutenus et nous positionne désormais au côtés des plus grands cabinets internationaux.
Liens :